Precision
Finds every word and every object — not just a rough section
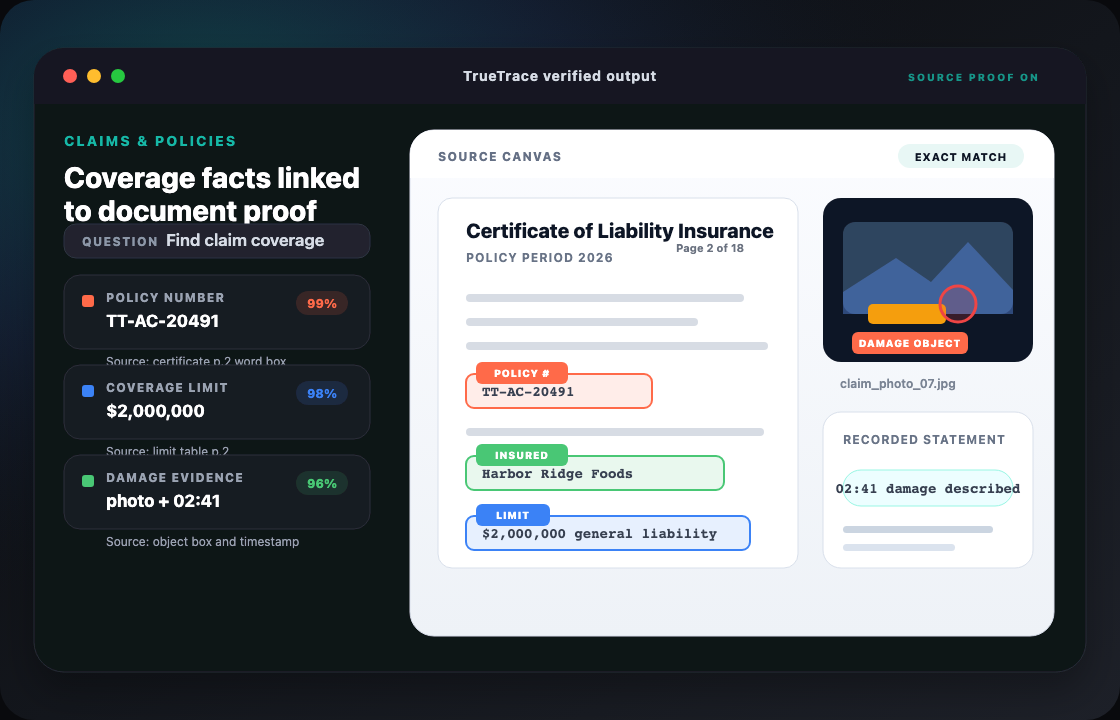
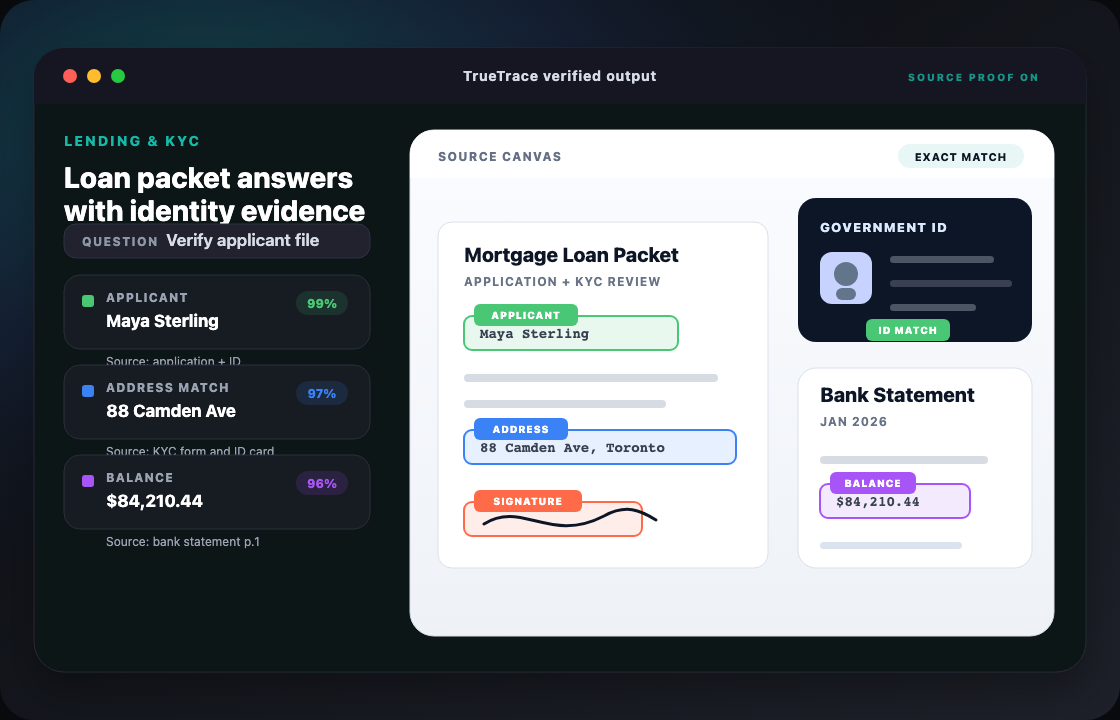
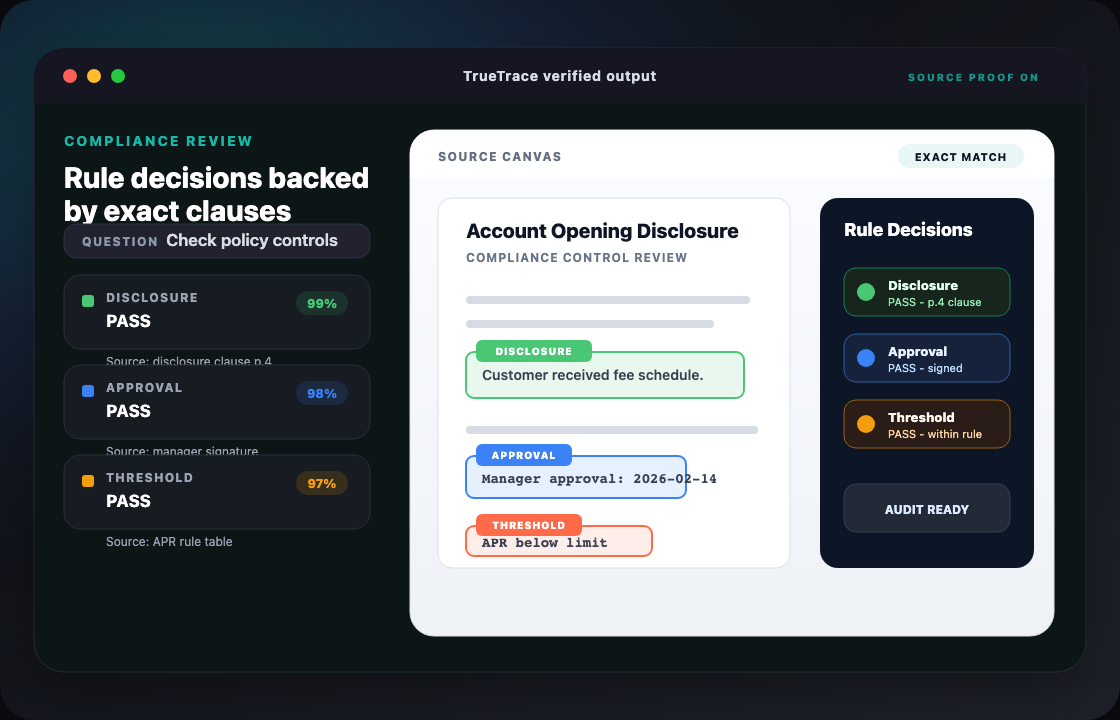
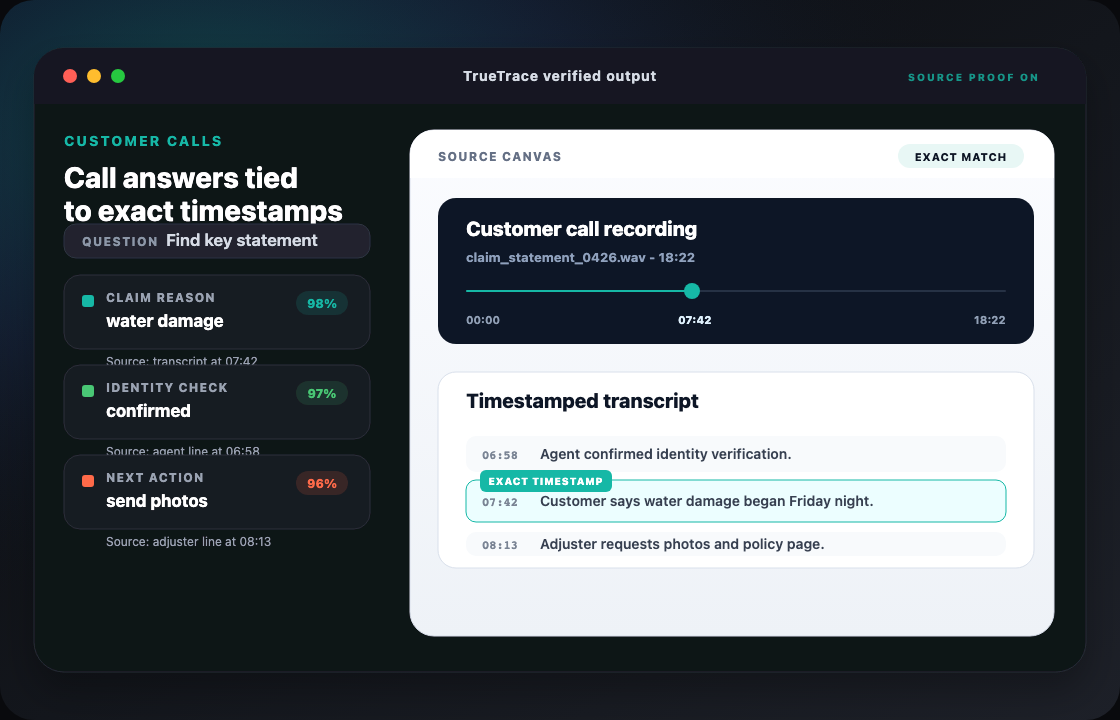
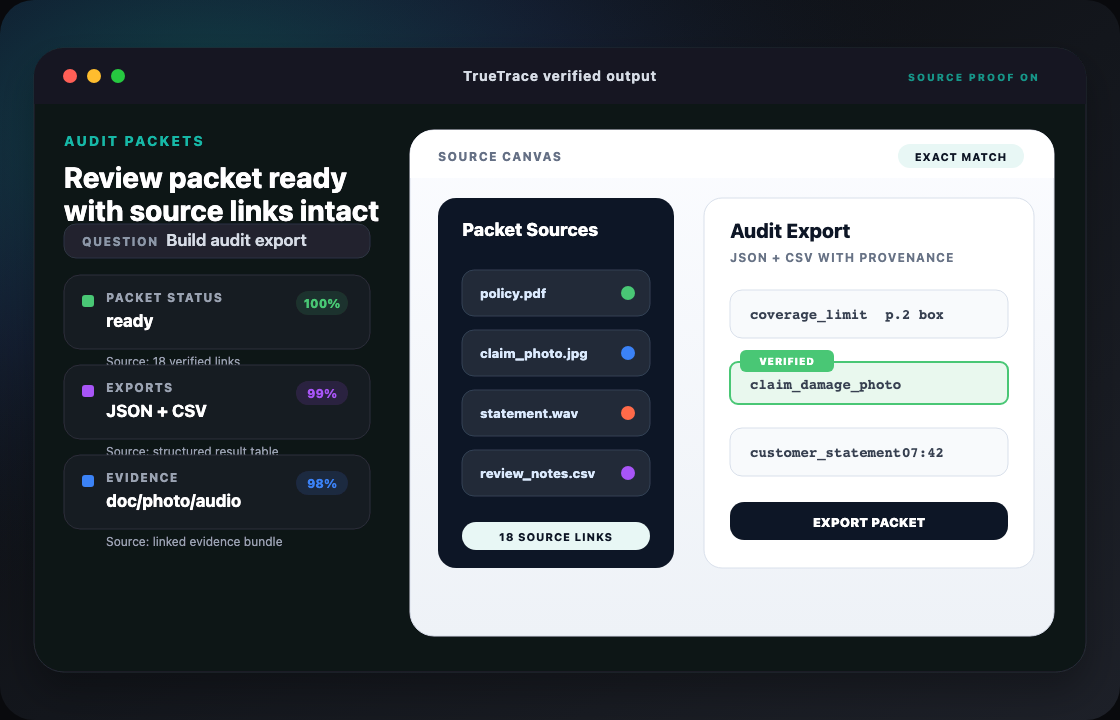
Most document AI tools narrow an answer down to a paragraph or section. TrueTrace goes further: it locates the exact word on the page, and also recognizes objects in images — people, vehicles, equipment, signatures, logos, damage, safety gear. So when you ask "where is this?", you get a pinpoint, not a shrug.
word-level text location
object detection in images
audio & video timestamps